LLM Council - 現代のMAGIシステム
LLM Councilとは
Section titled “LLM Councilとは”- 複数のLLMを仮想的な評議会のメンバーとし、回答の多様性と品質を高める仕組みを提供するAIエージェント
- OpenAI初期メンバーでTeslaのAutopilot部門でのキャリアを持つ Andrej Karpathy が開発したこともあり、少し話題になった
- ちなみにAndrej KarpathyはVibe Codingの提唱者でもある: https://x.com/karpathy/status/1886192184808149383
- GitHubリポジトリ: https://github.com/karpathy/llm-council
補足: MAGIシステムとは
Section titled “補足: MAGIシステムとは”- MAGIシステムはエヴァンゲリオンに登場する意思決定システム
- 人類側が重大な意思決定を迫られる局面で登場
- MELCHIOR-1(メルキオール、理性)、BALTHASAR-2(バルタザール、情緒)、CASPER-3(カスパー、本能)という3つの判断主体から構成される
- 意思決定は多数決で行われる
- チャットインタフェースを通して、複数のモデルに対してプロンプトを同時に投げる
- 各モデルは他のモデルの回答を匿名化された状態で読み、正確性・洞察などに基づく評価・ランク付けを行う
- 指定した議長モデルが、初期回答とピアレビューから最終回答を合成する
- 多数決ではなく議長が最終回答を出すという意思決定プロセスがMAGIシステムとは大きく異なる
技術スタック
Section titled “技術スタック”- インストール
$ git clone https://github.com/karpathy/llm-council.git$ cd llm-council/$ uv sync$ cd frontend$ npm install$ cd ...env- プロジェクトルートに
.envを作成する - OpenRouterで発行したAPIキーを設定する
- プロジェクトルートに
OPENROUTER_API_KEY=sk-or-v1-...backend/config.py- 使用するモデルを変更することもできる
...COUNCIL_MODELS = [ "openai/gpt-5.1", "google/gemini-3-pro-preview", "anthropic/claude-sonnet-4.5", "x-ai/grok-4",]...- サーバを起動
$ ./start.sh- 起動直後の画面
- プロンプト
この質問に対して、複数のLLMがどのように異なる前提・観点・リスク認識を持つかを比較し、その違いを踏まえた上で最終的にどの結論に収束するかを示してください。
問い:LLMを単体で利用する場合と、評議会(Council)方式で利用する場合では、どの種類のタスクにおいて品質差が最も顕著に現れるか。具体例と、その理由(単体LLMの典型的な失敗モードと、Councilでそれがどう変わるか)を説明してください。- 体感1〜2分待った
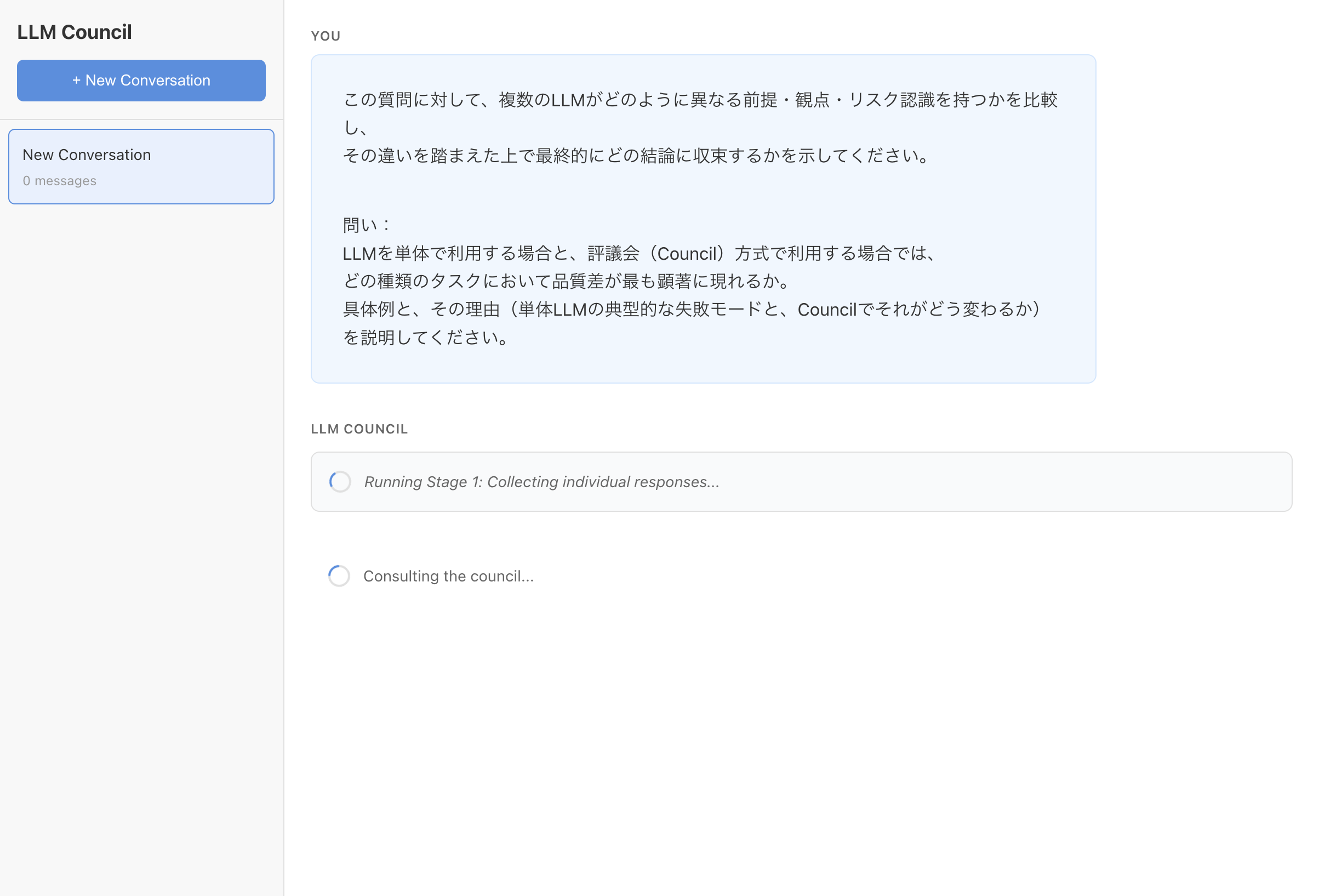
- 各モデル毎のレスポンスが見れる
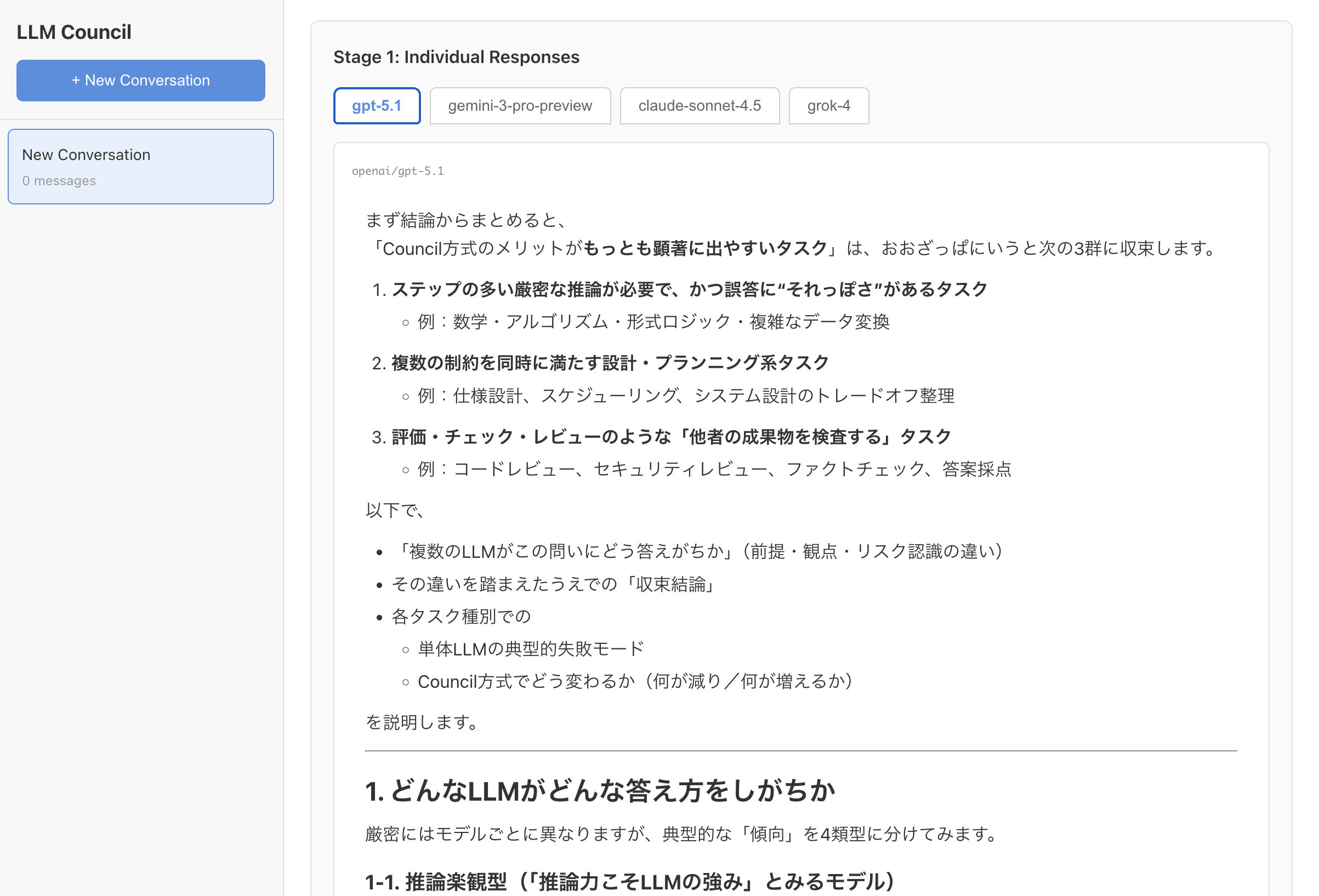
- ランク付けされる

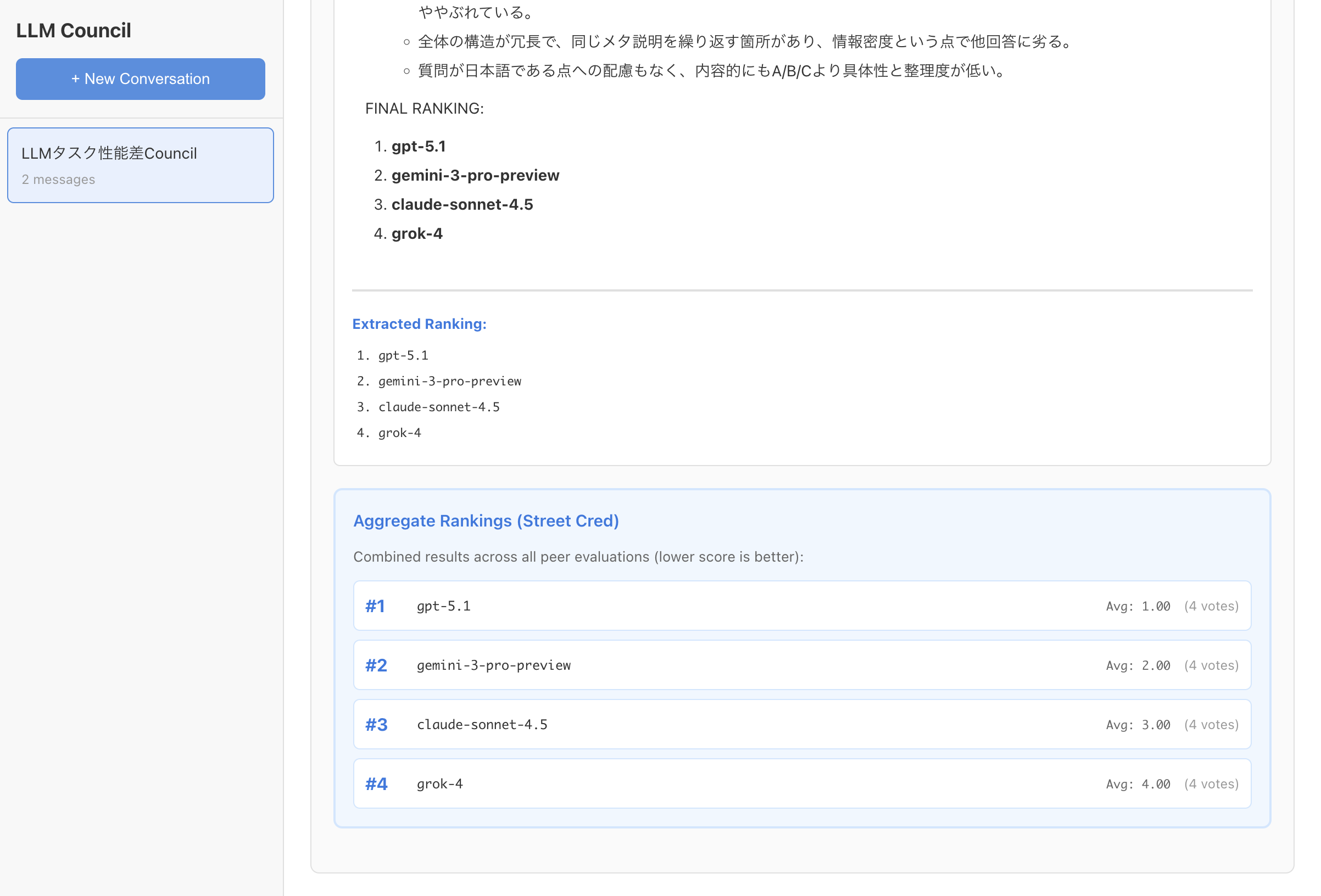
- 最終的な回答が生成される
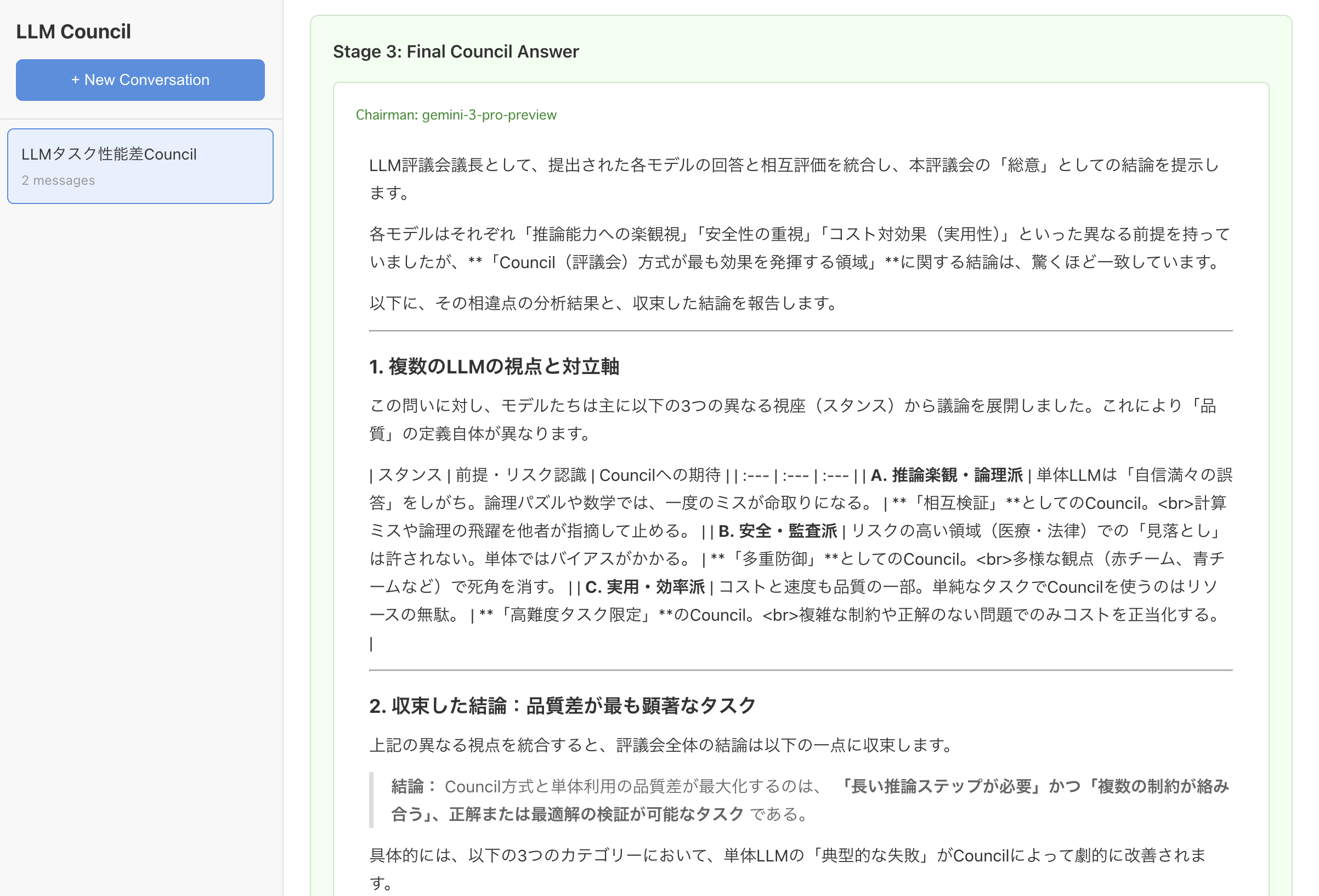
- レスポンスがストリーミング対応していないこともあり、レスポンスは遅く感じる
- 検証で数回使用した程度なので、これで回答の品質が上がっているどうかの判断はできていない
- シンプルな構成ながらも面白いコンセプト
- 自分でも何かしらAIエージェントを自作してみたい(現代のシビュラシステムとか?)